
Aksel Acar
|

Emilien Coudurier
|

Nathan Tabet
|

Cyprien Tordo
|

Cedric Zanou
|
Preparation
Context
Reddit is often described as a platform or a collection of communities. In our study, we invite you to see it differently: as a vast archipelago. Islands (subreddits) each with their own cultures, norms, and languages, are connected by invisible currents of hyperlinks, references, and shared users. Most days, these currents carry harmless conversation. But sometimes, something else travels with them... Earlier this year, several monitoring organizations raised an alert: a mysterious virus has been detected. This virus was not biological, but behavioral: patterns of toxic behavior appeared to be spreading across Reddit in ways that resembled contagion rather than coincidence. Hostile language, harassment, and inflammatory content were no longer confined to isolated communities. Multiple variants seemed to have emerged, spreading in atypical ways across interconnected communities and making the dynamics of the epidemic unusually complex.
To investigate this digital virus, the World Health Organization (WHO) mandated our team of epidemiologists equiped with a Minor in data analysis: AdAstra. Our goal is not to moralize or moderate, but to observe, map, and understand the investigate the epidemiology of toxicity in Reddit’s hyperlink network. Specifically, this study seeks to answer three key questions:
- Variant characterization: Can we identify and clearly define the different variants of toxicity circulating in the Reddit archipelago?
- Community mapping: How do these variants manifest across different types of communities, and are certain subreddits particularly associated with specific types of toxicity?
- Inter-community influence: Through selected case studies, can we trace how individual communities influence each other and understand potential causal pathways in the spread of toxic behavior?
This notebook presents our research and results as we navigate the Reddit archipelago, examine clusters of related communities, and track how toxic behavior emerges and propagates through the network.

Reddit is a large, community-driven social media platform structured around user-created forums known as subreddits. Each subreddit centers on a specific topic (ranging from news, politics, and science to niche hobbies and pop-culture interests) and functions as its own semi-autonomous community with distinct norms, moderators, and posting cultures. Interactions on Reddit occur primarily through posts and comments, and one subreddit can reference another by including a hyperlink within the text or title of a post. These cross-subreddit links form what is known as the Reddit Hyperlink Network: a web of directed connections that reveals how information, discussions, and community attention flow across the platform.
Our Tools for the Mission
As part of our mission, the WHO provided us with detailed records of interactions between communities across the Reddit archipelago. Unable to visit the islands directly due to the risk of contagion, we rely on these essential tools to investigate the virus remotely and effectively. Specifically, we make use of the following three datasets:
- Reddit Hyperlink Network (Post Bodies): A directed record of how subreddits reference one another through hyperlinks embedded in post content, annotated with time, sentiment classification, and 86 textual features that allow us to track toxic interactions as they occur.
- Reddit Hyperlink Network (Post Titles): A complementary dataset capturing the same type of interactions, but originating from post titles
- Subreddit Embeddings: A set of 300-dimensional semantic representations for each subreddit, encoding thematic similarity and latent relationships between communities beyond explicit links.
Reddit Hyperlink Network Datasets
The Reddit Hyperlink Network models interactions between subreddits through hyperlinks embedded in Reddit posts. Two complementary datasets are used: one dataset containing hyperlinks appearing in the body of posts, and one dataset containing hyperlinks appearing in post titles.
Both datasets share the same structure. Each row corresponds to a directed interaction from a source subreddit to a target subreddit at a specific point in time. In addition to the subreddit identifiers, each interaction includes a timestamp, a binary sentiment label (±1), and 86 properties describing the textual content from which the hyperlink originates.
In the context of this project, the focus is on the toxicity of the message, regardless of whether the hyperlink appears in the body or the title of a post. As a result, the two datasets are concatenated into a single dataframe and then reordered chronologically.
Subreddits Embeddings
This project also uses precomputed subreddit embeddings to incorporate semantic information into the analysis. Each row in this dataset represents a subreddit encoded as a dense numerical vector of dimension 300. These embeddings capture latent semantic relationships between subreddits learned from Reddit activity and provide a complementary perspective to the explicit hyperlink network.
Before tracing any outbreak, we needed to understand the terrain. Using the subreddit embeddings, we immediately projected Reddit into a two-dimensional space, transforming an abstract network into a navigable landscape of clustered islands and thematic regions (subreddits with less than 20 total interactions over the period were discarded). Doing so, we were able to produce the Reddit map that guided us throughout our study. For the first time, the scale of the challenge became visible...
Methodology overview
- Designing a metric to detect and quantify toxicity
- Toxicity scoring using linguistic features
- Toxicity binary classification, combining score and sentiment
- Classifying different toxicity propagation styles
- Selectioning features characterizing toxicity propagation
- Identify different toxicity propagation styles (clustering)
- Inject clusters onto the Reddit embeddings map
- In-depth case studies - Focus on restrained time-windows and limited subreddits to study
- Study case 1: "bettersubredditdrama"
- Study case 2: "science"
- Study case 3: "drama"
Toxicity measurements
Before any outbreak could be tracked, one critical problem had to be solved: raw data alone cannot diagnose an epidemic. To study propagation, we first needed a reliable and consistent way to detect and quantify toxicity at its source: the individual Reddit post.
We define toxicity as patterns of communication or behavior that create a hostile, disrespectful, or harmful environment for participants. This can include insults, harassment, hate speech, excessive negativity, or attempts to provoke conflict. Toxicity reduces constructive discussion, discourages participation, and can damage the overall health and cohesion of the community.
Exploiting the 86 textual properties
Our dataset includes 86 textual properties covering structural, lexical, emotional, and LIWC-derived indicators. While these features were not originally designed specifically for toxicity detection, they collectively capture many linguistic correlates of antagonistic or degrading speech.
Properties 1 to 18 capture surface-level linguistic and structures of the text. They measure the basic composition and readability of a message, including its length, complexity, and word or sentence structure. They include metrics such as character and word counts, fractions of different character types (letters, digits, punctuation, etc.), sentence length averages, and readability scores. Together, they provide a quantitative snapshot of how the text is written rather than what it expresses.
Properties 19 to 21 represent sentiment analysis metrics, derived using the VADER (Valence Aware Dictionary and sEntiment Reasoner) model. They aim to measure the emotional polarity of the text. It includes the Positive Sentiment, Negative Sentiment and Compound Sentiment. These features reflect the emotional valence of the language used.
Properties 22 to 86 are purely lexicon-based ratios, derived using a text analyis tool called Linguistic Inquiry and
Word Count (LIWC). Each LIWC represents the proportion of words in a text that belong to a certain lexicon: LIWC_X = (nb words in lexicon X)
/ (total nb words). While useful to see the presence of a certain vocubulary in a post, they remain purely lexical and don't treat emotion
or sentiment in any way.
Below are some metrics that are promising to use, based on our qualitative defintion of toxicity.
| Dimension | Description | Example of properties to use |
|---|---|---|
| Negative | Measures strength of negative emotion |
Neg_Vader, LIWC_Negemo,
LIWC_Anger, LIWC_Anx…
|
| Aggressive | Captures hostile or taboo language |
LIWC_Swear, LIWC_Sexual,
LIWC_Death, LIWC_Relig…
|
| Targeting | Focus on others (potential hostility toward people/groups) |
LIWC_You, LIWC_Humans,
LIWC_Social…
|
| Not cognitive | Opposite of reasoned or analytical tone |
LIWC_Insight, LIWC_Cause…
|
| Violent and short | Style indicators of impulsive or aggressive speech |
Number of UPPERCASE words,
Readability index…
|
While the VADER scores seemed promising (optimized for social media texts and posts), they mainly work like a LIWC score and calculate emotion of the language that was used (like an advanced lexical repertory of words that are conventionally considered negative or harmful on social platforms). This cannot be considered an accurate measure of negativity in our context. For example, some shortfalls of lexical metrics include:
- Sarcasm, irony, and context: Commenting “Stupid guy” in a link targeting a funny video of a guy slipping or in a link targeting a video of a political speech doesn't embody the same negativity.
- Cultural difference in language: Some communities are (by culture) founded on “offensive” language without being negative. For example, a CallOfDuty subreddit will frequently mention terms like "kill" or “assassination”. These words are not toxic in that community, but could be considered so in other subreddits (ones not related to war or gaming).
Because toxicity in our definition must reflect true negative intent, not just negative words, lexical sentiment proves insufficient.
Exploiting sentiment classification
LINK_SENTIMENT is derived using a supervised sentiment classifier trained on manually labeled Reddit data.
When labeling, the authors have taken into account their human judgement of context, irony etc. in addition of a purely lexical analysis.
So this binary sentiment classifier is designed specifically for inter-subreddit interactions and is our most reliable (categorical)
measure for pure negativity.
To understand which properties meaningfully contribute to negative interactions, we compare normalized mean property values between positive and negative links. Comparing group means detects systematic differences in linguistic patterns (and normalization accounts for differing scales and distributions across features). We naturally expect toxicity-related linguistic features to cluster more strongly in negative posts. Identifying features more common in negative interactions ensures alignment with our conceptual model (toxicity requires negativity).
- A difference of 0.25 standard deviations corresponds to a small-to-moderate effect size. In textual and psychological data, small-to-moderate effects are often meaningful because language patterns are inherently noisy and multidimensional. A 0.25 cutoff ensures that weak or negligible features are excluded, while features with clear group differences in positive vs negative sentiment are retained. This balances strictness with comprehensiveness.
- As we explained above in our definition of toxicity, it cannot be captured by a single marker but arises from a constellation of linguistic behaviors. Well-validated toxicity models (Google Perspective API, Jigsaw toxicity challenges...) incorporate dozens of features, not just a few. On the other side, if the metric relied on too many features, it would risk misinterpreting domain-specific vocabulary as toxic and producing high-variance estimates for minority communities. Using ~20 features distributes the metric across a reasonably broad linguistic base, improving stability and most importantly cross-subreddit generalizability.
- 20 features is consistent with dimensionality in psycholinguistic instruments. Psycholinguistic tools like Empath (200+ categories) or Biber's Dimensions of Register Variation (50+ linguistic dimensions) show that meaningful linguistic traits require between 10 and 30 variables to capture reliably.
To summarize these arguments, retaining 20 properties maximizes informational coverage, ensures robustness across heterogeneous subreddits, matches standard dimensional expectations from psycholinguistics, and corresponds to a statistically meaningful effect-size cutoff. The threshold of 0.25 therefore strikes the optimal balance between inclusiveness and discriminative power.
The figure highlights how each properties differ between positive and negative links after z-score normalization, emphasizing features with the largest contrasts. Hovering reveals the underlying property names and quantitative differences.
Toxicity scoring
Based on the conceptual qualitative choice of what defines toxicity and the empirical negativity analysis above, we select a subset of properties to constitute our toxicity metric and build a weighted average of them. These properties already exist in ratio form (0–1), ensuring comparability.
TOXICITY_SCORE: Continuous metric that measures the toxicity intensity in a subreddit post.
Scoring is defined as a weighted linear combination of the selected properties. A linear model is appropriate because it balances interpretability (and will allow immediate examination of feature contributions) with simple comparison across subreddits. It also supports later scaling, standardization, and model-based refinements. Weights are based on informed judgments from literature on aggressive discourse (e.g., strong weight on anger and swearing; negative weight on cognitive complexity features like insight or cause).
Weights are normalized by the sum of absolute values. This choice preserves relative influence of features and rescales the score into a bounded and interpretable range. Il also ensures no single feature arbitrarily dominates due to coefficient magnitude. This normalization is a standard approach for interpretability when working with heterogeneous features and manually chosen weights.
The following table presents the selected properties to build the toxicity score, with their linear weights. The figure visualizes the relative importance of selected properties in the toxicity scoring; slice size reflects coefficient magnitude while color encodes sign. Hovering over the slices reveals the exact feature name and weight.
| Property | Weight |
|---|---|
| NEGATIVE_SENTIMENT_CALCULATED_BY_VADER | 5 |
| LIWC_SWEAR | 5 |
| LIWC_ANGER | 5 |
| FRACTION_OF_STOPWORDS | 1 |
| LIWC_SOCIAL | 1 |
| LIWC_HUMANS | 1 |
| LIWC_NEGEMO | 1 |
| LIWC_SEXUAL | 1 |
| LIWC_CAUSE | -5 |
| LIWC_INSIGHT | -5 |
| FRACTION_OF_DIGITS | -3 |
Toxicity binary classification
We now have a reliable, continuous measure of toxicity. But it's not necessarily easy to interpret directly...
We would like to accompany this continuous metric with a binary classification: "Is this toxicity score value sufficiently high?
In other words, is this message toxic?" To answer this question, we design a binary classification by passing a threshold on TOXICITY_SCORE.
Specifically, the threshod above which messages are flagged as toxic is the quantile-75 of the toxicity scores distribution. That is, we
mark as significantly toxic the top 25% messages with highest score. We also enforce that only messages with negative sentiment can be classified as toxic.
TOXICITY_CAT: Categorical metric that classifies posts as non-toxic (0) or toxic (1).
Why is the quantile-75 of the distribution interpretable and consistent?
- Toxic behavior is statistically rare — and tail-based thresholds reflect this. Online toxicity is considered to be heavy-tailed in the sense that most posts are neutral, while toxic ones are relatively rare and concentrated at the upper end of the distribution. Selecting the upper quartile (top 25%) isolates the long tail of intense language but ensures coverage of sufficiently frequent abusive content. Thus, the 75th percentile is a natural and theoretically grounded boundary.
- 75th percentile ensures class balance suitable for downstream modeling. Binary classification tasks require a non-trivial positive class to avoid degenerate models. Cutting at 90% would lead to the positive class being too small (5–10%), sparse, with high variance. Cutting at 50% would lead to the positive class being too large, not aligned with toxicity rarity.
- The 75th percentile is conceptually aligned with “significant toxicity”. By definition, we want to classify only strongly toxic posts as toxic. Choosing the top quartile is a reliable way to identify posts with unusually high use of aggressive markers and atypical linguistic patterns. This makes toxicity classification interpretable and consistent across subreddits.
Using only the threshold-based classification, we obtain the following cross-counts:
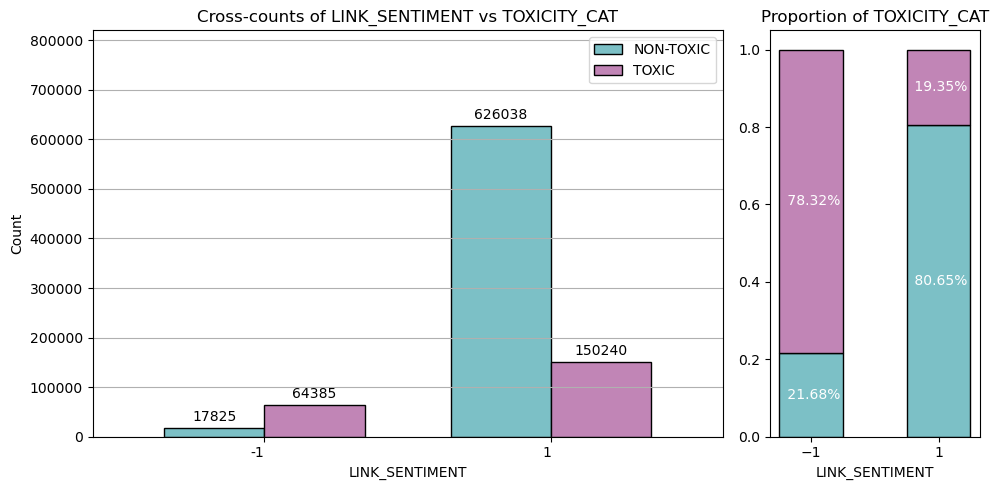
At first, it appears that the majority of toxic messages are actualy labeled positive, which is not desirable as we explicited that, in our context, toxicity only comes with negativity. However, looking at the proportions of toxicity in each sentiment class (right barplot), we see that around 78% of negative messages are labeled toxic, while only 19% of positive messages were. Negative messages are much more likely to be toxic (which makes sense based on the properties we retained to define toxicity).
To finalize our binary classification, we enforce the rule that only messages with negative sentiment (LINK_SENTIMENT = −1) can be classified
as toxic (TOXICITY_CAT = 1). This decision is based on a conceptual definition of toxicity as hostile, harmful,
or abusive discourse, which fundamentally requires a negative emotional valence. Although positive/neutral-sentiment messages may
sometimes contain high levels of features like swearing or anger, classifying them as toxic would introduce significant false positives that
do not align with the standard understanding of online harassment or abuse.
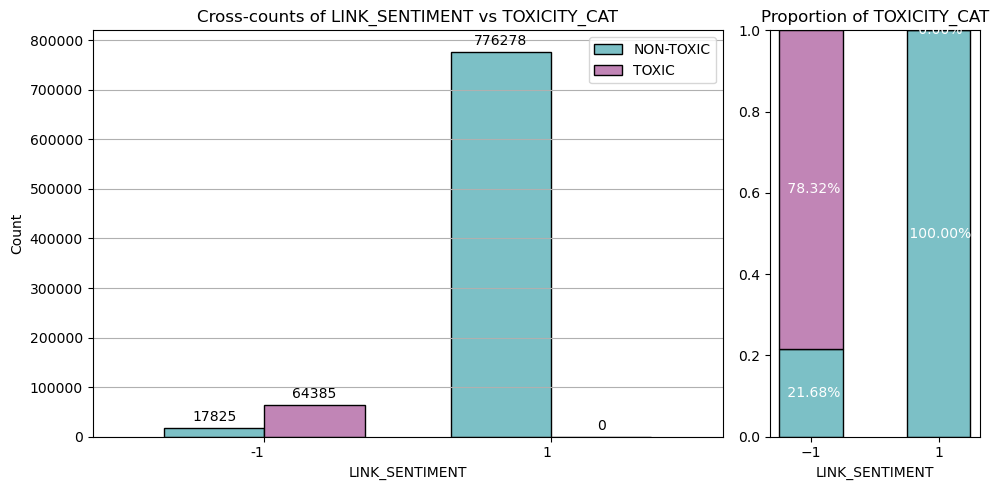
Note that the continuous TOXICITY_SCORE is preserved even for the links that are ultimately filtered out by the sentiment check. This score serves as a
crucial linguistic feature intensity metric, quantifying the sheer presence of aggressive or low-quality language features (e.g., swearing, anger, simplicity)
independent of the link's overall "true" sentiment. By keeping the raw score, we retain valuable information for later analysis, such as comparing the
distribution of strong language features across both toxic (negative sentiment) and non-toxic (positive sentiment) messages, which can reveal linguistic
patterns related to intense discourse beyond just negative intent.
Our team could move beyond theory and into observation: we returned to our initial map of the Reddit archipelago and colored each island (subreddit) according to its toxic interactions count over time.
This map gave us a first overview on the dynamics of the epidemic: pockets of intensity appear, gradients form across regions, and clusters seem to pulse with activity. And yet, patterns are not clearly emerging yet... While the map confirms that something was happening, it doesn't really explain anything yet. We needed to go beyond raw intensity and focus on structure. Our next step is clear: to identify and cluster the different variants of toxicity propagation shaping the Reddit space.
Propagation styles
Clustering toxicity propagation to identify variants
As the investigation progressed, it became clear that the virus did not spread in a single, uniform way. Much like a pathogen with multiple strains, toxicity exhibited distinct temporal and behavioral patterns across the Reddit archipelago. Some communities acted as chronic carriers, others showed sudden outbreaks, while some primarily received or reciprocated toxic interactions.
To identify these variants, our team selected a set of features capturing toxicity over time, incoming and outgoing toxicity, and the intensity and reach of interactions between communities. By clustering subreddits based on these indicators, we uncovered four distinct propagation styles, each representing a different “variant” in how toxicity emerges, persists, and spreads across the network.
Source (agressor) temporal features
src_tox_count: Total number of toxic interactions sent.src_active_span_days: Duration between the first and last toxic interaction sent.src_median_gap_days: Median time gap between consecutive sent toxic interactions.src_gap_cv: Variability of time gaps between sent toxic events.src_max_30d_count: Maximum number of toxic interactions within any 30-day window.src_event_rate: Average rate of sent toxic interactions over the active period.src_pct_events_recent: Proportion of sent toxic interactions occurring in the most recent period.
Target (victim) temporal features
tgt_tox_count: Total number of toxic interactions received.tgt_active_span_days: Duration between the first and last toxic interaction received.tgt_median_gap_days: Median time gap between consecutive received toxic interactions.tgt_gap_cv: Variability of time gaps between received toxic events.tgt_pct_events_recent: Proportion of received toxic interactions occurring in the most recent period.
These temporal features capture differences between sustained and episodic behavior, regular versus bursty activity, and increasing or declining toxicity over time.
Network features
net_out_degree: Number of distinct subreddits targeted by toxic interactions.net_in_degree: Number of distinct subreddits sending toxic interactions.net_reciprocity: Proportion of bidirectional toxic relationships.
Network features describe how subreddits are embedded in the toxicity network and help distinguish isolated aggressors, frequent targets, reciprocal conflicts, and highly connected communities.
Together, these features provide a multidimensional representation of toxic behavior, enabling clustering based on behavioral patterns rather than simple toxicity volume.
Clustering Preprocessing
Before we could catalogue “variants” of toxicity, we had to do what any careful medical unit would do: discard unreliable samples and calibrate every instrument. Not every island has the same exposure: some see a handful of toxic encounters, others are ports where toxicity arrives daily. If we cluster raw measurements, K-Means mostly rediscovers size. So we preprocess to reveal behavioral variants, how toxicity persists, spikes, and travels. We apply four essentials: filter sparse islands, clean edge cases, tame outliers, and standardize units.
- Low-activity filter: keep only subreddits with at least 10 toxic interactions.
This avoids unstable temporal statistics (e.g., gap variability from 2–3 events). - Log compression (heavy-tailed counts/spans/degrees): X' = log(1 + X).
This reduces the dominance of a few very large communities in Euclidean distances and PCA. - Winsorization (bounded percentages): cap extreme values to limit leverage.
Useful for ratio-like features (“% recent”) where a some edge cases can skew centroids. - Mega flag: mark the top 1% on raw activity/degree as
is_mega.
We keep mega-subreddits in clustering, but track them explicitly for interpretation. - Standard scaling: (X − µ) / σ so units contribute comparably.
K-Means and PCA are distance/variance-driven so scaling prevents “days” or “counts” from winning by default.
Reduction through PCA
Even with redundant symptoms removed, we're still tracking 14 different behavioral indicators per community. That's a lot of data to process when trying to identify distinct virus variants. Principal Component Analysis (PCA) helps us lower the 14 measurements down to the core patterns that really matter. We are trying to identify key symptoms that define a disease: instead of tracking every minor detail, we focus on the fundamental signatures that distinguish one variant from another.
We keep enough components to capture 80% of the behavioral variance, basically retaining the most important diagnostic information while filtering out noise. This gave us 6 core "behavioral markers" that efficiently represent how different communities engage with toxic behavior, making variant classification clearer and more reliable.
Clustering with KMeans
With our refined behavioral profiles ready, we can finally classify communities into distinct toxicity variants. We use K-Means clustering, an algorithm that groups communities with similar behavioral patterns together. K-Means works well here because it efficiently handles our continuous measurements and produces clear, interpretable variant types.
The key challenge: determining how many distinct variants exist in our data.
How many toxicity variants are circulating in the Reddit archipelago? Too few categories and we'll miss important distinctions between different strains. Too many and we'll see differences where none truly exist.
We test different numbers of variants (K = 2 through 10) using two diagnostic measures:
- Silhouette score: Measures how well each community fits its assigned variant compared to other
variants. For each community i in variant Ci:
s(i) = (b(i) - a(i)) / max(a(i), b(i))
where a(i) is the average distance to other communities in the same variant (cohesion), and b(i) is the average distance to the nearest other variant (separation). Scores range from -1 to +1, with higher values indicating clearer, more distinct behavioral types. - Balance: Measures how evenly communities are distributed across variants, calculated as the ratio of smallest to largest variant size. A balance near 1 means roughly equal variant populations; near 0 means one dominant "catch-all" group.
We also run 100 stability tests for each K value using the Adjusted Rand Index (ARI) to ensure variant classifications are consistent and reproducible.
After systematic evaluation, K = 4 emerges as optimal: high clustering quality (silhouette ≈ 0.4), reasonable balance, and excellent stability (94% consistency across runs). Four distinct toxicity variants, each representing a genuine behavioral archetype.
Confirming the Variants (Cluster Validation)
Once clusters emerge, we treat them like a first diagnosis: plausible, but not yet proven. We validate from two angles: geometry (are clusters compact and separated?) and evidence (do clusters truly differ on the features?).
- Davies–Bouldin (DB): lower is better; penalizes overlap (high within-cluster spread vs. small separation).
A “worst-neighbor” style check: it highlights if any two clusters are hard to tell apart. - Calinski–Harabasz (CH): higher is better; rewards strong between-cluster variance relative to within-cluster variance.
A global signal of whether clustering explains meaningful structure (not just noise). - Kruskal-Wallis H-test: non-parametric feature-by-feature test; checks whether clusters have different distributions.
We apply a conservative multiple-testing correction (Bonferroni-style) and focus on the most discriminative features.
Results and Interpretation
It is now clear that the virus doesn't spread uniformly across the Reddit archipelago. Instead, it manifests through a limited number of recurring patterns which are distinct variants defined by how communities interact, over what time scales, and in which roles. This analysis revealed four distinct behavioral archetypes of toxic behavior, each characterized by its activity level, dominant role (aggressor or victim), and temporal dynamics.
| Cluster | Characterization | Count |
|---|---|---|
| Cluster 0 | Moderate-volume Agressor - Mixed | 228 (including 1 Mega) |
| Cluster 1 | Moderate-volume Victim-leaning - Mixed | 636 (0 Mega) |
| Cluster 2 | High-volume Balanced (Hub) - Bursty | 302 (including 24 Mega) |
| Cluster 3 | Low-volume Victim - Mixed | 198 (including 1 Mega) |
-
Cluster 0: Moderate-volume Aggressor – Mixed
These subreddits primarily send toxic messages but do so irregularly. They target multiple communities while rarely being targeted themselves.
Interpretation: periodic aggressors, often reacting to specific events rather than sustaining long-term campaigns. -
Cluster 1: Moderate-volume Victim-leaning – Mixed
These communities receive more toxicity than they send, but still engage in retaliatory behavior.
Interpretation: controversial communities involved in ongoing conflicts, more often attacked than attacking, but not passive. -
Cluster 2: High-volume Balanced (Hub) – Bursty
Highly active communities with intense, reciprocal toxic exchanges occurring in short bursts.
Interpretation: central hubs where major conflicts erupt, often triggered by external events. The bursty behavior is explained as this cluster contains most Mega-subreddits. -
Cluster 3: Low-volume Victim – Mixed
Subreddits that almost exclusively receive toxicity without responding.
Interpretation: vulnerable communities subject to one-sided harassment, with little or no toxic output.
Pattern assignment (chronic / bursty / occasional). Thresholds are data-driven (tertiles).
We take the most frequent temporal_pattern inside the cluster (and keep its percentage as context).
- Chronic: high activity + low irregularity.
- Bursty: high short-window intensity + high irregularity.
- Occasional: low activity + large typical gaps.
- Mixed: A mix of the above categories
Volume assignment (low / moderate / high): we compute tertiles on all subreddits, then assign:
- High-volume if cluster median
total_tox_count_raw> Q0.67 - Moderate-volume if Q0.33 < median <= Q0.67.
- Low-volume otherwise
• Role label (aggressor / victim / balanced / leaning): we compare outgoing vs incoming toxicity using the
relative imbalance computed on cluster medians diff_ratio = abs(src - tgt) / (src + tgt), then assign:
- Balanced (Hub) if
diff_ratio< 0.20 - Aggressor or Victim if
diff_ratio>= 0.50 (depending on wethersrc > tgtortgt > src - Aggressor-leaning or Victim-leaning if 0.20 <=
diff_ratio< 0.50. - Inactive if
src + tgt= 0.
• Mega-subreddits: We print how they distribute across clusters (transparency, not a separate type).
Together, these propagation styles form a concise map of how toxicity spreads, escalates, and concentrates across the Reddit archipelago. The result of this clustering can be visualized in the following map. This map is not the geographic representation of Reddit from the 300-dimensional embeddings. Instead, it is a virtual, statistical map in which each point represents a subreddit positioned according to the similarities in its toxic behavior. Hover on the map to explore how islands reorganized!
Marking variants on the Reddit map
We now want to see how well the identified variants align with the geographic structure of the Reddit archipelago: we color the islands in our original embeddings-derived map according to their toxicity propagation style. Subreddits that are not toxic and thus unlabeled are assigned to Cluster -1.
The result provides a striking view. The immediate observation is that subreddits that are geographically distant in the embedding space can share similar toxic behavior, while neighboring communities may follow very different dynamics. But at the same time, some regions clearly display a dominant variant of toxicity behavior.
With the Reddit archipelago fully mapped and the diverse variants of virus propagation clearly identified, the terrain is no longer unknown and our instruments are calibrated. But understanding patterns from afar is only the first step: true insight comes from going into the field.
Equipped with our clusters and toxicity metrics, we prepared to conduct focused case studies. These are targeted, in-depth investigations of smaller regions within the Reddit landscape, restricted to specific time windows and selected subreddits. We designed 3 case studies cases. By zooming in on these representative clusters, we aim to capture the dynamics of toxicity in action: which communities amplify it, which absorb it, and how bursts ripple across connected islands. And so, the team embarks on this next stage of the mission: collecting fine-grained evidence and understanding the mechanisms behind toxicity propagation in the Reddit archipelago...
Case studies
We aim to deepen our comprehension of the toxic events through particular examples. By performing an analysis on a specific time period and for a carefully chosen set of subreddits, we expect to highlight previously-discussed behaviors, and discover additional ones.
First, we select an interesting group of subreddits.
- A typical subreddit part of a clustered behavior (high-volume balanced (hub) - bursty, low-volume victim - mixted, ...) is chosen and its associated habitual neighbors are identified. To this set of neighbors, we add all subreddits interacting with the initially chosen subreddit. Note that the union is kept, since some of its neighbors may interact with it. This selected subreddit is called the protagonist

Second, we take a reduced time window.
- From daily interactions over the whole time period (January 2014 to April 2017), we assess peaks and compare them with daily negative interactions over the same period. A period of interest is qualitatively picked.
Third, we assess if the event is toxic or not.
- The event is defined as the time series in the selected window of the total negative interactions of all subreddits within the chosen group. Its nature is assessed from the daily activity of the group, and most active subreddits (overall and toxic active) are highlighted. From the trend of negative interactions, we decide if this event is a potential toxic one.
Finally, we analyze the life cycle of the event.
- We perform a causal inference analysis using the PCMCI algorithm, reconstructing a causal graph between the most active subreddits time series and the protagonist. This allows us to identify catalysts and true actors in the event, as well as attenuators. Furthermore, death of the event is assigned to passive or active.
In this section, we will refer to 'global' in order to indicate a temporal state, meaning over the whole time period available in the original dataset. Comparatively, 'total' will be used to speak about the sum of interactions over subreddits (spatial meaning). This is made to avoid confusion between total interactions and global interactions.
Here below you will find the results for each Case Study, where the protagonists are:
- bettersubredditdrama (Cluster 0: Moderate-Volume aggressors)
- science (Cluster 1: Moderate-Volume victim-leaning)
- drama (Cluster 2: High-Volume balanced hub)
Note that the fourth cluster was not explored as a case-study as it is low-volume, and therefore the associated time series contain less exploitable data.
Click on the red pins on the map to explore each case.
bettersubredditdrama
(Cluster 0)
science
(Cluster 1)
drama
(Cluster 2)
Study Case 1: bettersubredditdrama
Study Case 2: science
Study Case 3: drama
Time Window Identification
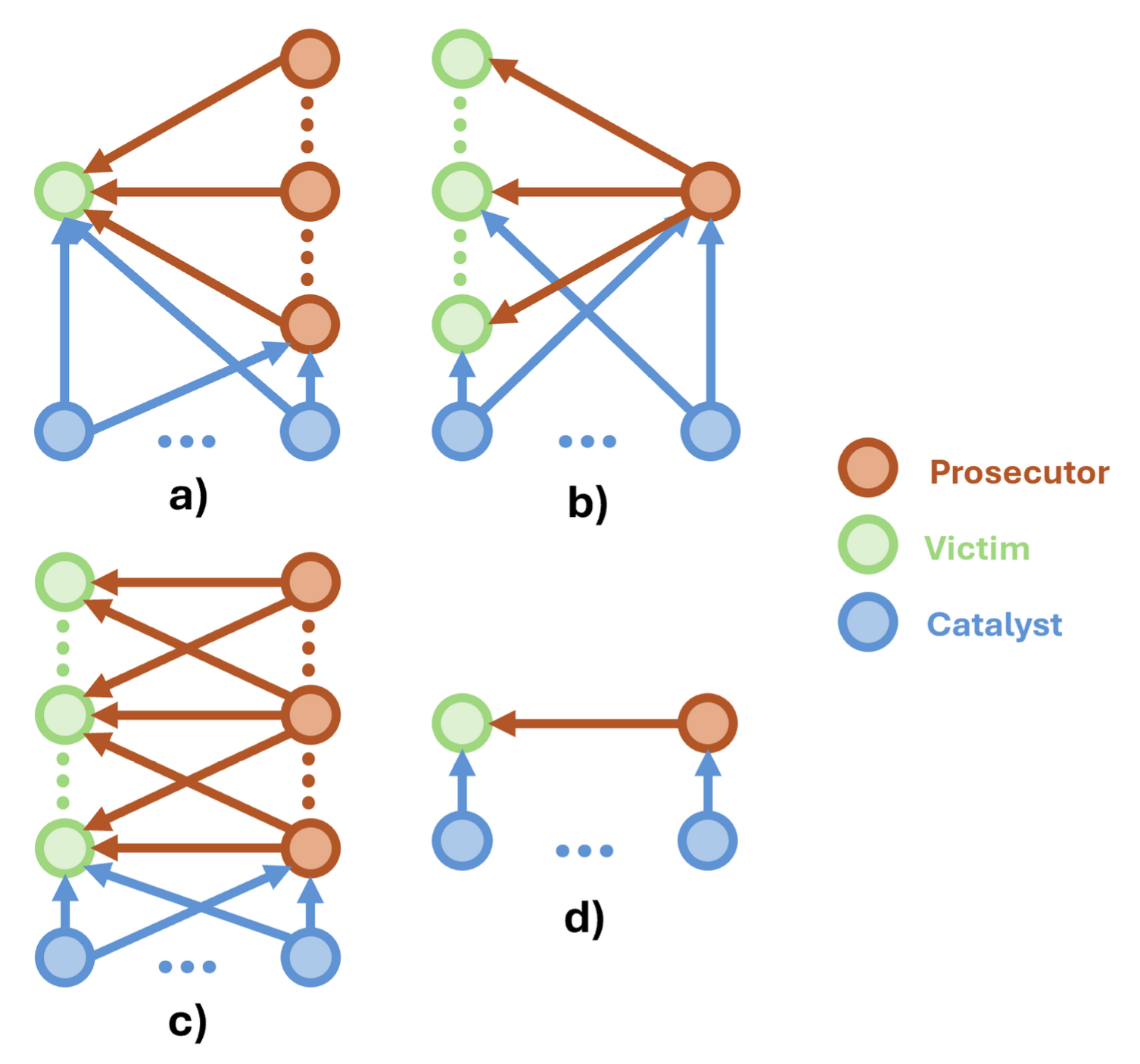
Figure: Toxic event classes
- a) Single Victim, Multiple Prosecutors
- b) Multiple Victims, Single Prosecutors
- c) Multiple Victims, Multiple Prosecutors
- d) Single Victim, Single Prosecutor
Red arrows show toxic interactions, blue arrows non-toxic interactions. High source interactions indicate multiple victims, and high target interactions indicate multiple prosecutors. Note that cases where two very active subreddits show both high interactions might be confused for c) or d) equally if no further analysis is done. Catalysts subreddits act indirectly on the event (not necessarily through toxic interactions), and are hard to identify. This is the main reason why neighbor subreddits are selected in addition to interacting subreddits, and we argue that these habitual neighbors are the most likely to act as catalysts. However, such complex interlinked social dynamics cannot be guaranteed to be perfectly modelled this way. As for observational studies where external undetected confounders have underlying effects, we cannot construct a causal analysis encapsulating every confounder with 100% certainty. Moreover, while every scenario may exist, we highlight that most of the toxic events happening in reddit tend to c). Note that prosecutors, victims and catalysts can be labelled as 'participants' for generalization, and that roles are time-varying. Additionally, each interaction (toxic or not) can either have an exciting or attenuating effect, and are not represented in the schematic. They will be assessed in the last part (causal analysis), based on positive or negative correlation of time series.
The 'bettersubredditdrama' is particular as it was active only for a short period. However, we can see that the toxic-to-nontoxic ratio of interactions in this period is moderately high, and constant. This makes it a potential chronic toxic subreddit in its lifespan. Furthermore, it almost only interacts as a source, validating its 'aggressor' nature found by clustering.
The 'science' subreddit was subject to numerous bursty events. One of them appears as a dominant toxic event over the whole period and could be interesting to investigate for its rapidly changing behavior. Moreover, most of its interactions over the whole time period are as target, indicating a victim nature (same as clustering prediction). We highlight that the nature of the selected peak between April 15th and May 5th is consistent with this observation, meaning it can also be classified as a victim event.
The 'drama' subreddit is one of the most active on reddit. It has a toxic peak resembling the one of 'bettersubredditdrama', which makes sense from their thematic closeness. However, its number of interactions is way higher and possesses context before and after, making it non only interesting in itself, but also interesting to compare with the first case study. We can see that the number of source interactions is dominant, indicating an aggressor behavior (consistent with clustering). We therefore select a time window slightly larger than the first case study (i.e. from November 1st 2015 to January 1st 2016) in order to take into account bigger time series data.
Toxic Event Assessment
U usual neighbors-based), and the interactions within this time window.
451 subreddits were found to be interacting with 'drama' over the focused time window. This suggests a toxic event with multi victims (class b or class c based on the toxic event classes). Some of its typical interacting network (habitual neighbors) were indeed interacting with it in this period. Most of them (95%) were not interacting directly, but may be catalysts. That is, they may have effects on its interacting subreddits (analogue to a confounder variable) without having direct connection with it.
For the 'science' subreddit, 158 other subreddits were found to be interacting with it over the chosen time window. From its victim nature, this suggests a multi-aggressor scenario (class a or c based on the toxic event classes). None of its habitual neighbors are part of these interacting subreddits, but may still be catalysts. That is, they may have effects on its interacting subreddits (analogue to a confounder variable) without having direct connection with it.
Numerous subreddits (815) are interacting with the 'drama' subreddit. This makes sense as it is a very active subreddit overall. We also note that some habitual neighbors (8%) are part of the interacting subreddits. Because of its high number of source interactions and the high number of interacting subreddits, we assess that this outbreak is linked to a multi-victim scenario (class b or class c based on the toxic event classes). While 92% of its typical interacting network is not directly interacting in this period of time, they may have effects on its interacting subreddits (analogue to a confounder variable) without having direct connection with it.
Total Interactions Over Time
As mentioned previously, this part allows us to discuss if an interaction outbreak indeed appears in the chosen time window. Moreover, the dominance of one type of interaction (source or target) gives information about the class of toxic event it is. In instance, a high source-to-target ratio indicates that most of the focused subreddits interact towards external subreddits, meaning a typical aggressor behavior.
As seen in the global interaction plot, the interactions of 'bettersubredditdrama' are condensed in a short period. We can see more clearly that the total interaction curve overlaps the total source interaction curve, indicating as stated earlier an aggressor behavior. This confirms the clustering belief. Note that a time step of 12h has been set to distinguish more clearly the trends, and to reduce aggregation of data.
In order to identify more precisely the trends and source-to-target interaction ratios, we use a finer time step of 6h in this plot. Data is therefore less aggregated and in addition to the focus on the selected time window, we can assess that the date of concern is around 18:00 on April 23rd 2015. A majority of target interactions shows a victim-type event for the 'science' subreddit, confirming our prior clustering belief. We can also see another interaction outbreak on April 15th 2015, but we need to see the amount of toxic interaction to assess if it is relevant to our study.
From this plot, we can say that the prior belief obtained with clustering is true. A significant amount of source interactions compared to the target ones indeed indicates an aggressor behaviour. Within this focused time window, it is easier to assess that the total number of interactions indeed went up for an extended period (roughly a month). Compared to the first study case, we have a clearer context to compare this outbreak to. Further analysis with the plot of toxic interactions will provide useful information to establish if an extended toxic event indeed took place.
Top subreddit interactors
From this bar plot, we can conclude that this event is indeed a single prosecutor, multi-victims case (case b). The 'bettersubredditdrama' subreddit is clearly interacting exclusively as a source, meaning the toxic interactions it may have are necessarily as source as well. This is most likely a prosecutor, which is interesting considering its short lifespan. We can hypothesize that it was a highly participating actor in propagating toxicity, and we will verify this hypothesis in the top toxic subreddit interactors section.
As conjectured, the 'science' subreddit is a victim during this event. We can also see that other subreddit have a significant number of interactions, some mostly as target ('askscience'), some as target and source equally ('badsocialscience', 'asksciencefiction'), and some completely as source ('brain_damage'). This indicates we are in a multi-victims, multi-aggressors case (case c). We can highlight that the most active source subreddits are thematically opposed to science, with 'brain_damage', 'badsocialscience', 'conspiracy' and 'badscience' showing up in the top 10 interactors. Furthermore, the 'asksciencefiction' might actually be a false positive, as it has the same keyword in its name but might not interact directly with the 'science' subreddit. We need to see if all these subreddits interact in a toxic manner to confirm these statements.
This bar plot confirms our prior belief on the nature of the 'drama' subreddit. Indeed, this subreddit has a high source-to-target interaction ratio, indicating an aggressor nature. What is very interesting is that we can see that the 'drama' subreddit is not the most active in his group. We can conjecture that the subreddit with the most impact is 'subredditdrama', followed closely by 'bettersubredditdrama'. This also links this study case to our first one, showing underlying connections. Since the 'bettersubredditdrama' subreddit has no target interaction, it means the bigger subreddit 'subredditdrama' never targeted it. Moreover, this absence of 'subredditdrama' in the first study case indicates that the bigger subreddits don't actually communicate, but rather focus on multiple, smaller victims. This is key in defining the type of toxic event, and suggests that these subreddits are allied against smaller victims.
Note that from how our focusing tool is built, every subreddit with a keyword appearing in their name is selected. This ensures no false negatives, but also adds false positives. We argue that this is not an issue as the causal analysis will reveal if it is the case.
Toxic Interactions Over Time
TOXICITY_CAT == 1.
Average daily toxicity: 0.075, Average toxic duration: 161.96 hours. The average toxic duration is the average time separating
an interaction labelled as TOXICITY_CAT == 1 and another one labelled as TOXICITY_CAT == 0 for the same subreddit.
Even if it is a bit less than a week, one toxic interaction per day for a week should not be considered a toxic event. We
define that a significant outbreak of toxicity >> average daily toxicity is a bursty toxic event, and that high daily toxicity
levels for a longer period than a week is considered a long-term toxic event.
It is clear from this plot that the amount of toxic interaction is non-negligible over the selected period. Even if we don't have much context in such a short lifespan, it can be argued that the whole period of existence of this subreddit is equally toxic, and sufficiently toxic to be considered a chronic toxic subreddit. We emphasize that a typical subreddit has globally close to no toxic interaction, while the moving average here is fluctuating around 4 toxic interactions per day. We conclude this is a toxic event, with 'bettersubredditdrama' as the protagonist. Its role in the event will be identified in the next sections.
From the moving average, we can assess that this is a bursty toxic event. The rest of the context (toxic interactions around the peak) shows that this subreddit is usually not involved in toxic events. We can also say that the previous outbreak seen in the total interaction plot was not a toxic outbreak, but simply an interaction outbreak.
As for the first study case, this event can be classified a long-term toxic event. The trend given by the 3-day average shows an overall increase in the number of toxic interactions over the course of a month, which is long enough to be considered long-term. Since this subreddit is already on average more toxic than the average, this even more toxic period is considered as a long-term toxic event.
Top Toxic Subreddit Interactors
As for the top interactors, the 'bettersubredditdrama' subreddit appears as the dominant toxic interactor. This confirms our conjecture about its role as the principal aggressor in its group. The number of toxic interactions, combined with its interactions being mostly as source, makes it a typical hyper aggressor towards multiple victims.
We can see that the 'science' subreddit is still in the top 3 of most toxic interacting subreddits. However, we highlight that the first and second subreddits were not that high in the total interaction bar plot. The previously identified antithetic subreddits do not turn out to be the most toxic in the 'science' group. Nevertheless, their non-toxic interactions could turn out to have an effect on the toxic interactions of the 'science' subreddit, as catalysts would do. Additionally, the number of toxic interactions is very low (5) compared to the number of total interactions (80). This is still a toxic event for the subreddit in itself, but on a different scale. We highlight that this kind of bursty toxic event is common for small subreddits, especially because the average daily toxicity indicates less than 1 out of 10 toxic interactions. Even an outbreak of 5 toxic interactions is relevant in our study, and provides useful data on the different scales of such events.
As in the bar plot of top interactors, 'subredditdrama', 'bettersubredditdrama' and 'drama' dominate as the most active toxic interactors. This further entails their role as major aggressors. We can say they probably form the aforementioned alliance as prosecutors, propagating toxicity to numerous victims without interacting with one another.
Top Toxic Subreddit Interactors
PCMCI: Distinguish causal relationships (based on time series data, from spurious correlations) by taking into account autocorrelation and confounding variables.
1/ PC Phase
- Uses a simplified PC algorithm to identify a set of potential parents for each variable
- For each variable, tests conditional independence with lagged versions of all variables
- Iteratively removes spurious links by conditioning on increasingly larger sets of past variables
- Output: A preliminary causal graph with candidate parent sets for each variable
2/ MCI Phase
- Refines the results from the PC phase
- For each remaining link, performs a more rigorous conditional independence test
- Conditions on the parents identified in the PC phase to determine if the link is truly causal
- Tests independence at specific time lags
- Output: Final causal graph with strength and significance of causal links
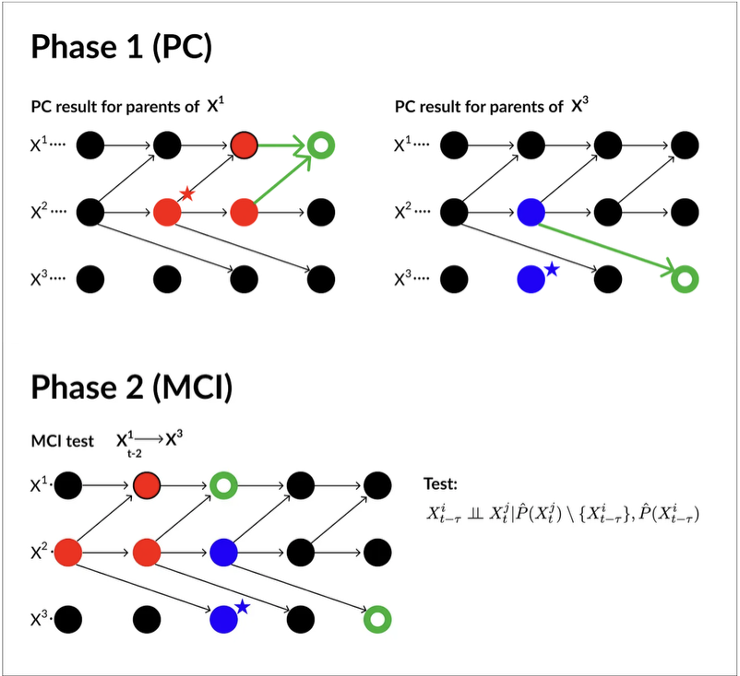
Figure: PCMCI steps. Red nodes: conditioning set for X³_t; Blue nodes: conditioning set for X¹_t; Star: False Positives. (Adapted from [1])
Different conditional independence tests can be used, including partial correlation (linear gaussian), rank-based/robust partial correlation, GPDC (nonlinear dependence via Gaussian processes), CMIknn (General conditional), Regression Conditional Independence (residual independence after regression) and Partial Correlation with Weighted Least Square. In our case, the robust partial correlation makes more sense, as it is usually used for social interaction data. Note however that it may miss nonlinear dependencies.
The tigramite library is used to perform PCMCI on our time series data (see [2]).
- one to assess causality between the toxic interaction time series of the protagonist and the non-toxic interaction time series of relevant subreddits,
- the other to assess causality between the toxic interaction time series of the protagonist and the toxic interaction time series of relevant subreddits.
Red links are positively correlated and green links are negatively correlated. Colored links are only drawn towards or from the protagonist. Lag is also shown, and indicates the time taken from one time series to affect the pointed node. As mentioned in the early phase of this section, such social links form a complex web of interlinked connections. PCMCI allows us to determine statistical dependence and correlation between time series, but is not a magical tool. The obtained causal graph is a representation of the causal interactions through statistical relevance, based on our assumptions. For example, we only analyze the most active subreddits, while the real connections are most likely the result of hundreds of low interacting subreddits. Unmodelled confounders indeed have an effect that cannot be seen in this graph, giving a simplified final analysis. This is also why only the protagonist is analyzed, since it reduces the number of links to take into account. We highlight that the graphs we obtain make sense as the effect on one subreddit is never considered from a single source.
From these causal graphs, we can identify subreddits having a direct effect on the protagonist. The entire graph shows a complex web of causality, which is expected since we work with complex social data.
A very interesting finding lies in the effect of non-toxic interactions from subreddits that have a direct impact on the protagonist’s toxic interactions. Among others, 'conspiracy' and 'anarchism' exhibit a positive correlation in this sense, meaning they act as catalysts. On the other hand, 'adviceanimals' appears to have an attenuating effect on the toxic trend at first (1-day lag).
The protagonist itself also has an effect on others, meaning that other subreddits may follow its trend due to its influence. This is the case for 'adviceanimals', which is positively correlated with the protagonist after some time (3-day lag). This highlights an interesting dynamic, where the effect of one subreddit on another is not symmetric in the opposite direction.
Furthermore, the protagonist’s trend is negatively correlated with the trends of non-toxic interactions in 'pics' and 'relationships', indicating that the number of non-toxic interactions drops when the number of toxic interactions of the protagonist increases. No calming links were highlighted here (i.e., non-toxic time series negatively correlated with the toxic time series of the protagonist), which suggests a passive decay of the toxic event.
The second causal graph confirms the aggressor behavior of the protagonist. Indeed, its positively correlated directed links towards 'conspiracy', 'pics', and 'hiphopheads' indicate a propagation of its own toxic trend. It also appears to be influenced by other subreddits, such as 'drama', 'worldnews', and 'relationships'. An especially interesting causal link is observed with 'anarchism', which shows a strong negative correlation towards the protagonist. This suggests that toxic interactions within 'anarchism' lead to a significant drop in the number of toxic interactions of the protagonist after approximately 2.5 days. This could indicate that 'anarchism' acts as a toxic attenuator, calming the trend through toxic interactions.
From these causal graphs, we can identify subreddits having a direct effect on the protagonist. The entire graph shows a complex web of causality, which is expected since we work with complex social data.
The first graph reveals an intricate interaction between the protagonist ('science') and four other subreddits. Notably, 'everythingscience' was previously identified as an additional victim alongside 'science', while 'badsocialscience' was identified primarily as an aggressor, although it also received some toxic interactions. Here, we observe that the number of toxic interactions of 'science' is highly correlated with non-toxic interactions of 'everythingscience' and 'badscience', suggesting that toxic interactions of 'science' propagate to others via non-toxic interactions with a small lag (12 hours).
The strong negative correlation with 'conspiracy' indicates that a toxic event affecting 'science' leads to a corresponding decrease in the number of non-toxic interactions of 'conspiracy'. Finally, the 'badsocialscience' subreddit shows a highly correlated link towards the toxic interactions of the protagonist, indicating that its non-toxic interactions are likely to trigger a toxic event involving the protagonist. We can therefore assess that 'science' is indeed part of a victim group, and that 'badsocialscience' contributed to this toxic outbreak. No calming links were identified here, suggesting once again a passive decay of the toxic event.
The second graph provides additional insight. In particular, the 'badscience' subreddit emerges as one of the most likely patient-zero candidates. Its low-lag, highly correlated link towards the protagonist suggests strongly coupled dynamics and thus a significant influence. We can also highlight the important influence of the protagonist on 'badsocialscience' and 'conspiracy', as previously mentioned.
A particularly interesting dynamic appears in the time-varying nature of the 'science' → 'badsocialscience' link: it is strongly positively correlated at low lags (6 hours) and strongly negatively correlated at higher lags (24 hours). Lastly, we observe that 'conspiracy' is positively correlated, indicating that not only do non-toxic interactions decrease when the protagonist’s toxic interactions increase, but its toxic interactions increase as well. We can therefore conclude that 'conspiracy' plays the role of a prosecutor, as suggested in the top-subreddit-interactors analysis.
Note that 'brain_damage' was identified as a false positive, as it exhibits no causal links with any other subreddit, neither through non-toxic nor toxic interactions.
From these causal graphs, we can identify subreddits having a direct effect on the protagonist. The entire graph shows a complex web of causality, which is expected since we work with complex social data.
The first graph reveals an intricate set of interactions between the protagonist ('drama') and several other subreddits. Since we previously identified this subreddit as an aggressor allied with 'subredditdrama' and 'bettersubredditdrama', we focus primarily on these links. We observe that 'drama' is influenced by several catalysts. In particular, the number of non-toxic interactions of 'anarchism' is positively correlated with its toxic interactions, suggesting that 'anarchism' may act as a patient-zero.
We can also observe the effect of the protagonist on others. Notably, 'subredditdrama' and 'bettersubredditdrama' show a decrease in the number of non-toxic interactions when 'drama' exhibits increasing toxic interactions, suggesting a coupled dynamic among allied subreddits, as previously conjectured.
The second graph highlights a tight relationship between the main drama-related subreddits, including 'subredditdrama', 'mildredditdrama', and 'drama'. This confirms our hypothesis regarding their alliance-type dynamics. The role of the protagonist as an aggressor is further supported by its direct influence on the toxic interaction time series of 'relationships', which was identified as one of several victims.
Finally, we observe the presence of a negative autocorrelation link, indicating a self-calming behavior of the protagonist. This suggests that the toxic event ended through a low-activity decay.
No false positives were identified in this case.
Conclusion
To put it in a nutshell, we managed to confirm the aggressor behavior of the 'betterdramasubreddit' subreddit through a specific, in-depth case study. Its relatively low lifespan revealed the existence of an all-time toxic subject that strongly impacts other communities. We identified the nature of the toxic event as a long-term toxic outbreak, and clearly highlighted its victims as well as its most active interaction network.
We completed our study by providing insights into the propagation agents, removing false positives, identifying potential patient-zero candidates, and characterizing the death type of the event (passive, natural). Through this work, we gathered valuable information that helps us better understand the toxicity phenomenon and confirms our conjecture regarding the existence of distinct toxicity variants.
This case study also emphasizes the presence of complex and highly interconnected networks, for which the most reasonable response to such outbreaks would be moderation of interactions rather than isolated interventions.
To put it in a nutshell, we managed to confirm the victim behavior of the 'science' subreddit through a specific, in-depth example. The highly bursty nature of its toxic event demonstrated that such a phenomenon exists and follows dynamics distinct from long-term outbreaks. We identified this event as a bursty toxic event and highlighted its prosecutors, as well as the most relevant interaction network involved in the outbreak.
We completed our study by providing insights into the propagation agents, again removing false positives, identifying potential patient-zero candidates, and determining the death type of the event (passive, natural). These findings further contribute to our understanding of toxicity dynamics and reinforce our hypothesis regarding multiple variants of toxic behavior.
As in CS1, this case underscores the existence of intricate interaction networks, suggesting that effective mitigation strategies should focus on moderating inter-community interactions.
To put it in a nutshell, we managed to confirm the aggressor behavior of the 'drama' subreddit through a specific, in-depth case study. We demonstrated the existence of allied aggressor communities, and highlighted their tight dynamics extending beyond purely toxic interactions. We identified this event as a long-term toxic outbreak, and mapped its victims, its most active interaction network, and its allied subreddits.
We completed our study by providing insights into the propagation agents, removing false positives, identifying potential patient-zero candidates, and characterizing the death type of the outbreak as low-active and mostly natural. These results further validate our conjecture regarding toxicity variants and emphasize the role of coordinated dynamics between communities. Once again, this case illustrates the complexity of Reddit’s interaction networks.
Conclusion
Synthesis of results
In conclusion, our team was able to identify the different variants of toxicity circulating in the Reddit archipelago and how these variants manifest across different types of communities. In addition, we highlighted influence between individual communities and causal pathways in the spread of toxic behavior.
After building a new metric that allows to classify types of toxicity propagation, we observed their distribution on a thematic mapping of subreddits. In depth analysis of three specific study cases helped us confirm our prior beliefs on toxicity variants, propagation mechanics and network interactions.
The task we have decided to tackle is complex, and we are aware that further studies are still needed to consolidate the understanding of such events. Social interactions are inherently full of underlying effects and causes, and care should be taken when trying to find generalized answers.
Nevertheless, our dedicated team provided useful results in order to understand the phenomenon, bringing data-based, scientific value to the debate. From our gathered conclusions, we have no doubt our work will participate in helping the people of the archipelago.
Group contributions
- Aksel Acar: Propagation-style clustering, Repo management, Datastory
- Emilien Coudurier: Case studies (structure and analysis)
- Nathan Tabet: Reddit embeddings mappings, community exploration, toxicity evolution
- Cyprien Tordo: Metrics (toxicity scoring and binary classification), Website Design, Datastory
- Cedric Zanou: Propagation clustering, Repo management, Datastory